

[내가 만든다면] 우리 모임 Mbti 궁합


<내가 만든다면> 시리즈는 앱/웹 서비스들을 가지고, 백엔드 관점에서 ‘내가 만든다면 어떻게 할까’ 수다 떠는 시리즈입니다. 내용 이해를 위해, 소개하는 서비스를 한 번 써보시는 것을 추천드립니다. 현실은 예상과 다를 수 있고, 필자의 생각보다 더 나은 방식도 존재할 수 있습니다. 코드 예제는 시간이 된다면 만들어서 첨부하도록 하겠습니다.
우리 모임 MBTI 궁합
MBTI에 열광하고 있는 요즘, 유행을 타고 있는 서비스가 하나 있다. 우리 모임 MBTI 궁합이라는 웹서비스다. 자신의 MBTI를 입력해 공간(모임)을 만들고 링크를 공유하면, 다른 유저가 타고 들어와 MBTI를 입력해 자리를 채운다. 그러고 나면 서로의 궁합을 완전 그래프(complete graph) 포맷으로 알아볼 수 있다.
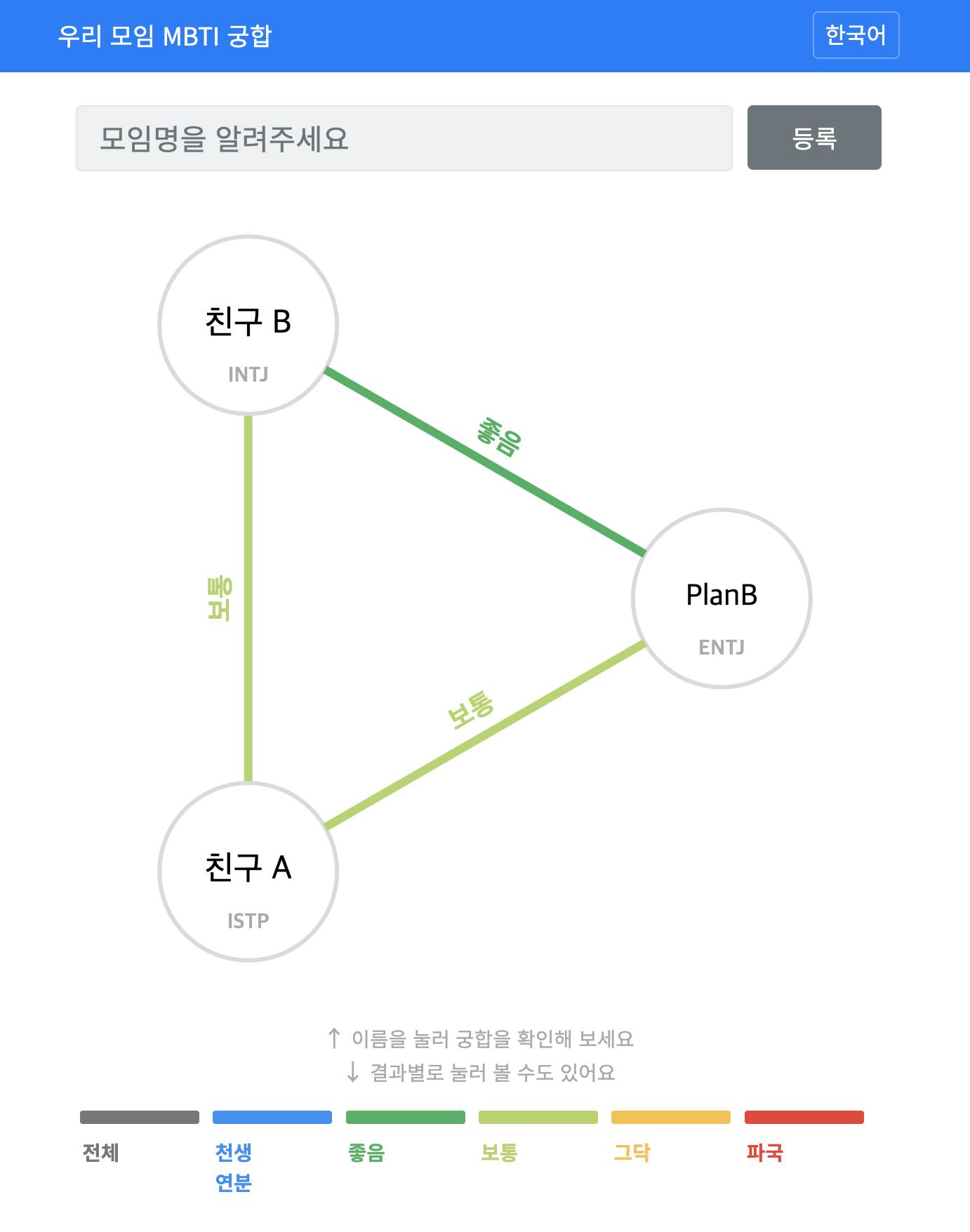
Backend
Abstract
백엔드 입장에서 사실 이 시스템은 꽤 간단하다. 모임별로 멤버 이름과 MBTI 정보만 저장하고 있으면 된다. JSON으로 구성한다면, 다음과 같다.
{
"모임A": {
"이름A": "INTP",
"이름B": "ENTP",
"이름C": "ESTJ"
},
"모임B": {
"이름A": "ISTP",
"이름B": "INTJ"
}
}
데이터 그 어디에도 ‘MBTI 간 관계'에 관련된 내용은 없다. 그러나, 데이터가 이렇게 raw하기 때문에 데이터를 쓰는 입장에서는 오히려 좋다. 어떤 format으로든 보여줄 수 있으니 말이다. 궁합을 보여주는 것은 단지 MBTI 데이터를 사용하는 한 가지 사례일 뿐이다.
어떻게 이게 가능할까? MBTI 간 관계 라는 relation은 서비스에 종속적이지 않은 상수이기 때문이다. 클라이언트가 들고 있어도 되는 데이터다. DB에 저장할 수밖에 없는, SNS 서비스의 친구나 follow같은 관계와 다르다.
Model
서비스를 사용하며 마주쳤던 기능들을 가지고, 서비스를 이루는 객체들을 좀 정리해보도록 하자.
Group
서비스는 모임이라는 개념에서 시작한다. 대충 group이라고 네이밍하겠다.
ID
Group에 ID가 필요하다. 말 그대로 group마다 identity를 두기 위함이고, 나는 이것을 그대로 모임의 공유 링크에 활용하고자 한다 (e.g. https://ddok9.com/ko/mbti/ecf22uAhJ 의 ecf22uAhJ 처럼). DB 관점에서는 Primary Key가 될 것이다.
여기에 auto increment int를 사용하게 되면, 임의의 group에 접근하기 쉬워지게 된다. 예를 들어 내가 만든 모임의 ID가 357이라면, 다음 모임의 ID는 358이 될 것이다. 유저는 본인이 만든 모임에 불특정 다수가 접근하는 것을 원하지 않을 것이므로, 보호할 방안을 생각해야 한다.
우리 모임 MBTI 궁합에서도 실제로 하고 있는 방법인데, random generate string을 ID로 두는 것이 일반적인 해법이다. URL에 들어가는 요소이므로 알파벳 대소문자 + 숫자 0~9로 만드는 것이 적합하다. 이제 ID의 길이를 생각해 봐야 한다. 결정은 10으로 했는데, 근거는 다음과 같다.
얼마나 많이 generate될 것인가? - 길이를 넉넉하게 잡아서, 중복 발생 가능성을 줄이자
random은 그 특성 상 중복을 확인해야 한다. 데이터가 많아질 수록 중복 가능성은 높아진다. 어떤 random string이 갖는 경우의 수가 100인 환경에서, 이미 30개가 저장되어 있다면 중복 가능성은 30%가 된다. 시간이 지날수록 중복이 자주 발생하게 되고, 최악의 상황에서는 무한루프가 발생할 수도 있다.
random string의 길이가 n이라고 했을 때, 경우의 수는 n^62가 된다. 예를 들어 길이가 1이면 62개까지 만들 수 있고, 길이가 4라면 14,776,336개까지 만들 수 있다. 길이를 하나만 늘려도 경우의 수는 62배 늘어나므로, 매우 넉넉하게 잡아주는 것이 좋다.
worst case를 생각해 보자. 서비스가 운이 좋아서 전 세계 사람들이 모임을 3개씩 만든다고 치면, 약 200억 개 정도가 만들어질 것이다. 62^6은 약 580억이므로, 길이가 6이어도 큰 문제는 없다. 그러나, 200억개라는 예상치 내에서 생각해 보면 중복 발생 가능성이 유의미한 수준(약 35%)이 되어 버린다. 무작위 문자열을 생성했는데, 중복된 것일 확률이 35%라는 것이다.
개인적으로는 worst case에서 중복 발생 가능성을 0.01% 이하로 유지하려는 편이다. 200억 개를 기준으로, 경우의 수는 200조가 되어야 한다. 값이 너무 커 보이지만, 길이가 8만 돼도 경우의 수가 약 220조 개가 된다.
0.01%라는 값에 특별한 근거가 있는 것은 아니다. 1%는 너무 크고, 0.001%까지 가면 과하다 싶은.. 당연히 서비스의 특성에 따라 달라질 수 있다.
임의 접근에 얼마나 안전한가? - crack의 관점에서
비밀번호를 0000부터 9999까지 다 눌러보듯, 경우의 수 처음부터 끝까지 시도해보는 것을 해킹에서 brute forcing이라고 한다. 현재 우리의 서비스는 ID만 알면 리소스에 접근할 수 있는 구조이므로, 해커의 임의 접근에 얼마나 안전한지를 생각해보는 것이 좋다.
앞에서 이야기한 길이 8(경우의 수 약 220조)을 기준으로, 모임이 200억 개 있다고 치자. 약 0.01% 정도를 차지한다. 그렇다면 임의 접근 10,000번 당 하나 정도가 발견된다고 볼 수 있다. random string의 길이가 1 늘어날 수록 brute forcing은 62배씩 어려워진다.
그렇게 예민한 데이터는 아니므로 길이가 8로도 적당하겠지만, 넉넉하게 잡는다는 생각으로 10으로 설정하도록 하자. 어떤 client가 임의 접근을 위해 수 백만 번씩 request를 한다면 인프라 수준에서 막히던 할 것이다.
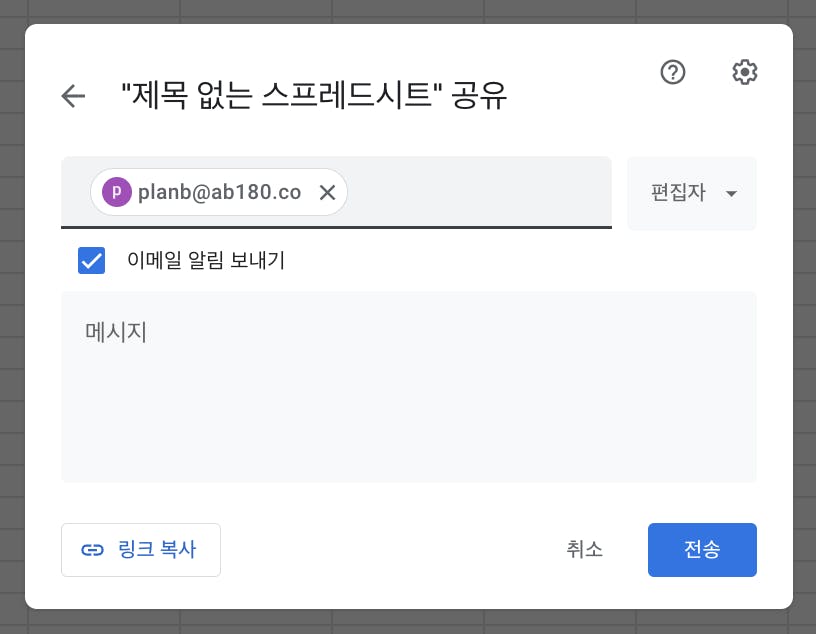
공유 링크의 임의 접근을 완전히 방어하려면, 회원가입 시스템을 만든 뒤 유저 단위로 공유하게 만드는 것이 좋은 방법이다. 다음의 Spreadsheet 공유 기능처럼 말이다.
여담으로, 중복이 발생했을 때 length stretching을 하는 경우가 있다. 예를 들어 길이가 10인 random string에서 중복이 발생했다면, 길이를 11로 늘려서 만드는 식이다.
주의할 점이 하나 있다. 패턴을 가진 seed로 ID를 만들지 말아야 한다. 예를 들어, auto increment id를 encoding하는 것은 주의할 필요가 있다. unique가 보장되므로 중복 제어를 할 필요는 없겠지만, 해커가 encoding algorithm을 알아낸다면 모든 ID를 알아낼 수 있게 된다.
Name
Group마다 이름이 존재한다. 이것은 user input이며 특별한 처리 과정이 없으니 딱히 이야기할 것이 없다. 만약 주소를 입력받는다면 해당 주소가 실제로 존재하는지 확인할 필요가 있겠지만, 이것은 그냥 단순한 이름이니 말이다.
validation만 조금 신경쓰면 된다. 문자열이니 min/max length만 정하도록 하자. 그리고 이렇게 이름같은 것은 uniqueless를 보장해야 하는지도 생각하면 좋다.
Member
Group 내에는 이름과 MBTI 정보를 가진 멤버들이 여럿 존재한다. 이름은 적당한 문자열로, MBTI는 Enum으로 관리하면 된다. DB 상에서는 4비트로 코드화해서 관리해도 무리는 없다(MBTI의 종류가 총 16개이므로). 오히려 스토리지도 덜 쓰고, Index같은 것을 걸 때도 유리하다. 대신 쿼리할 때 알아보기 힘드니 view같은 것을 만들어 두고, application layer에서도 적절히 추상화를 해 두는 것이 좋을 듯.
Service Limitation
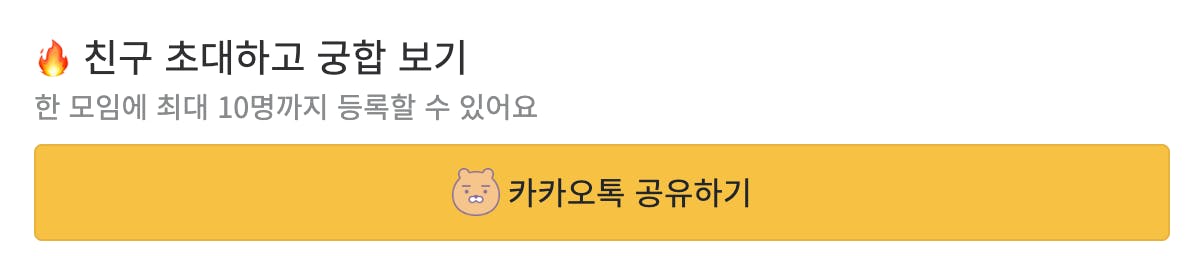
유저에 의해 선형적으로 증가할 수 있는 데이터는 limitation이 꼭 필요하다. 예를 들어 group에 member가 5000명 추가된다거나 하는 것은 기획 의도에 적합하지 않을 수 있다. 이런 부분은 엔지니어가 기획자에게 이야기할 수 있는 부분이다. 실제 서비스 내에서도 한 모임에 최대 10명까지 등록할 수 있다고 명시하고 있다.
DB
기본적으로 데이터의 schema가 정해져 있어 RDB가 적합하다. 테이블은 두 개가 나온다. Group 과 Member 를 관리하는 테이블이다.
CREATE TABLE `groups`
(
`id` char(10) NOT NULL PRIMARY KEY,
# random string. length가 고정되어 있으므로 char
`name` varchar(20) NOT NULL,
# length가 가변적이므로 varchar. max length는 20으로 가정
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP
# logging용으로 항상 하나씩 두는데, 습관이자 취향
);
CREATE TABLE `members`
(
`id` int NOT NULL AUTO_INCREMENT PRIMARY KEY,
# Identify를 위해 auto increment id를 pk로 둠
`group_id` char(10) NOT NULL,
# FK이므로 reference할 컬럼 타입과 맞춤
`name` varchar(20) NOT NULL,
# length가 가변적이므로 varchar. max length는 20으로 가정
`mbti` bit(4) NOT NULL,
# MBTI 유형 개수 16 == 2^4
KEY `members_group_id_fk` (`group_id`),
CONSTRAINT `members_group_id_fk`
FOREIGN KEY (`group_id`) REFERENCES `groups` (`id`)
ON DELETE CASCADE
ON UPDATE CASCADE
);
Application
DB 상으로 MBTI가 4비트로 코드화 되어 있으니, Persistent Layer에서 이것을 잘 추상화해주는 것이 좋다. Application 단에서는 HTTP API만 몇 개 열어주면 된다.
- 모임에 대한 Create, Read, Update
POST /groups- Group 추가
- ID를 random generate하며 적절히 중복 제어
GET /groups/{group_id}- Group 내 member들 정보 조회
PATCH /groups/{group_id}- Group 정보 수정. 현재 name밖에 수정할 수 없음.
- 모임에 MBTI를 기입하는 기능
POST /groups/{group_id}/members- name, mbti 받아서 적절히 DB에 적재
모임 생성 시 본인의 MBTI를 입력하게 되어 있는데, 이것은 모임 추가 API와 MBTI 기입 기능 API를 차례로 호출하면 된다.
Deployment
개인적으로 Amazon RDS + @ 조합을 좋아한다. DB는 RDS에 Aurora던 MySQL이던 써서 올리고, 어플리케이션은 Lambda로 올리는 것이 좋아 보인다. 유행에 따라 call 수가 급격하게 증가할 수 있기 때문인데, auto scaling을 직접 구성하긴 복잡하니, serverless 시스템이 유리해 보여서다.